Previous Story
¿Qué son las variables? Parte 2
Posted On 03 Ago 2015
Comment: 0
Las medidas de posición intentan resumir en una sola cantidad la información que brindan los datos recabados sobre una variable cuantitativa, por ejemplo la glucemia basal de 150 adultos, para expresarla o resumirla en un sólo número. Son medidas de posición la media y la mediana. La media es el promedio de los datos: suma de todos ellos y división por el número de observaciones. La mediana es el valor que ocupa el medio si ordenamos todas las observaciones de menor a mayor. Si el número de observaciones es impar, es justo el valor del medio. Si es par, el promedio de las 2 observaciones centrales. Corresponde al percentil 50 de una serie de observaciones: tiene por encima la mitad de las observaciones, y por debajo la otra mitad.
Las medidas de dispersión expresan cómo están los datos distribuidos alrededor de la medida de posición. La medida de dispersión de la media es el desvío standard. Para obtenerlo: a) se calcula la diferencia entre cada observación y la media y se la eleva al cuadrado; b) se suman todas esos cuadrados y a la sumatoria se la divide el número de observaciones menos 1; c) al resultado se le saca la raíz cuadrada. En símbolos:
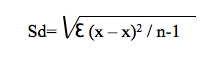
Entre la media +/- un desvío standard queda englobado aproximadamente el 68% de las observaciones; entre la media +/- 2 desvíos standard poco más del 95% de las observaciones.
La medida de dispersión de la mediana es el rango intercuartilo 25-75, que corresponde a los valores que ocupan el percentil 25 y el 75 en una serie de observaciones ordenadas de menor a mayor. Entre el percentil 25 y el 75 queda englobado el 50% central de las observaciones: un 25% queda por debajo del percentil 25 y otro 25 % por encima del percentil 75.
Si los datos tienen distribución simétrica o normal (se verá más adelante), media y mediana son similares; si la distribución es asimétrica la mediana representa mejor los datos, y es la que debe ser utilizada, porque la media es muy ”tironeada” o influida por los valores extremos. En los últimos años son muchas las publicaciones que utilizan mediana para presentar los datos de variables cuantitativas, por ser siempre confiables, y no depender de la distribución.
Las variables cuantitativas se grafican de varias formas, pero las más frecuentes son el histograma, el polígono de frecuencias, y el box plot, o gráfico de caja y línea.
Las variables no son una estructura rígida: pueden manipularse, y los datos presentarse de más de una manera. Por ejemplo: los datos de colesterol de 300 pacientes pueden presentarse como media con su desvío standard, o en una tabla de frecuencias indicando la frecuencia relativa de colesterol ≤ 100 mg/dl, entre 101 y 150 mg/dl, entre 151 y 200 mg/dl y así sucesivamente, expresando la frecuencia relativa de cada intervalo como un porcentaje, por ejemplo: 10% con cifras ≤ 100 mg/dl, 23% entre 101 y 15 mg/dl, etc.
Es altamente recomendable en el caso de las variables cuantitativas recolectar el dato como número; ya habrá luego tiempo para decidir cómo se trabaja con la variable. La categorización permite transmitir mensajes acerca de los datos, pero implica también pérdida de información. Por ejemplo: si se presenta el dato de la kalemia como hipokalemia sí/no (con valor de corte en 3,5 meq/l), no conoceremos el valor de potasio en cada categoría; no sabremos si los hipokalémicos tienen una media de potasio plasmático de 3,2 o 2 meq/l, y ello puede ser útil para comprender fenómenos fisiopatológicos o estimar pronóstico.
Dr. Jorge Thierer